打造專業的
智能影像解決方案
影像分析
人工智慧 ( AI ) 技術伴隨電腦運算能力大幅度提升,各產業逐步將智能化導入原本的場域中,透過 AI 技術的普及,過去需要花上幾個月才能做完的辨識分析工作,現在只要提供充足的歷史資料,就能從中抽絲剝繭在幾秒內提供精準的答案。在轉型升級的過程,又以視覺辨識為最能大規模優化整體流程,但在這其中,據數據統計只有不到 20% 的企業能夠成功導入 AI 視覺辨識,其中之一常造成專案失敗的主因,在於對來源影像的掌握度不高而造成影像延遲、辨識效果不佳等等。
延伸閱讀:必讀智能影像解決方案指南
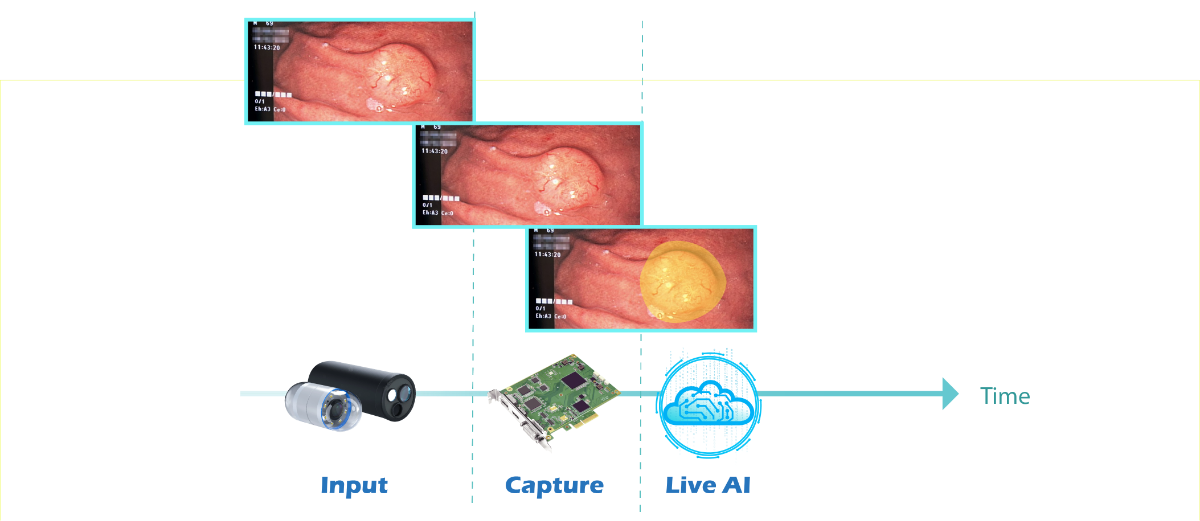
傳統上,系統整合商 ( System Integrator ) 會採用本地端或雲端兩種系統架構來對 AI 影像進行分析。早期是在一台電腦將影像擷取下來,丟到有辨識軟體的另一台電腦做分析,另一類是將擷取到的影像直接拋到像 IBM、Microsoft 或 Amazon 等具有辨識能力的雲端服務,透過網路蒐集回傳的分析結果,好處是雲端上已經佈署不同的 AI 模型,開發者可以直接套用,缺點則是影像隱私安全及時間延遲性。如果想要把延遲時間壓到極低,最好的辦法就是在電腦加入一張擷取卡直接取像後進行 AI 分析,這樣就能達到即時 AI 的效果,這種做法常用在需要進行邊緣智能運算的裝置中。
另外,也要理解 AI 的解法並不存在標準答案,一般軟體公司著重在研發技術的深度但不一定熟悉產業的痛點,如何充分了解客戶需求並打造客製化的解決方案,是開發者會面對的另一個挑戰。
聰泰由影像擷取卡起家在各領域深耕 30 餘年,累積廣泛性的產業知識,對於各類影像問題幾乎沒有隔閡,可以採用最快的速度釐清並切入,長期下來堆砌出難以動搖的競爭力。因此,聰泰在面對無法獨力開發 AI 的業者,可以透過 NexVDO SDK 原生的數十種影像分析模型與豐厚的產業經驗,協助客戶將原本的軟體智能化與產業對接 ;針對原本就是專精於 AI 影像分析的夥伴,其實更是需要 NexVDO SDK 擷取、錄影及串流模組的輔助,辨識分析結果往往取決來源影像的品質,聰泰在影像前處理可以做到尺寸統一、色彩空間轉換,讓你從前端就完全掌握影像品質及取像速度,而在影像後處理可以直接將影像與 AI 效果疊加將,讓原本的 AI 智能分析軟體比以往更即時更高效!
聰泰在 NexVDO SDK 在 AI 分析分為影像內容分析、生物識別及行為分析三大模組:
第一類影像內容分析模組應用於想要知道影像內有什麼特定物,或是這段影像發生了什麼事的情境。
延伸閱讀:邊緣AI常用的六大分析模組
在辨識上可以分為圖像分割 ( Segmentation ) 及物件偵測( Object Detection )兩種技術,以自動駕駛看到的影像來說,前者是將不同類別的物件分隔開來,例如道路、行人、車、樹、天空做分類,但物件偵測會進一步對車的種類做偵測,也就是辨識目前的大車是聯結車還是公車。這沒有哪一個方法比較好,而是要考量對於待解問題,哪一種能帶來較快速的效果。話說回來,辨識得出物件就能進一步延伸是要用來(1)分類計數 (2) 特徵比對還是 (3) 文本辨識。分類計數的應用有零售業的人流計數、 賣場熱區偵測 ; 特徵比對的應用可做到醫療產業的超音波腫瘤辨識、安防監控影像搜尋及跨鏡追蹤、工廠不良品檢測及生產自動化 ; 文本辨識是屬於辨識文字數字的範疇,舉凡像常見的智慧停車場車牌辨識、醫療資訊數位化等等。NexVDO SDK 提供人流及車流計數功能,像在交通上透過架在路口的攝影機影像,進行車況與行人的位置分析進而調整交通號誌的燈號,讓整體資源比以往固定燈號有更高效的安排。
延伸閱讀:鼎漢語聰泰合作打造AI智慧燈誌另外,聰泰在醫療產業也和相關醫療客戶合作開發,在工作站軟體中整合 NexVDO SDK 實現超音波腫瘤辨識,提供醫生做病兆即時輔助分析。
延伸閱讀:研華與聰泰攜手實現遠程醫療AI化 第二類生物辨識模組應用於在畫面上想要得知人臉相關資訊的情境,首先,要先了解所要做的人臉應用範疇為何,是要做人臉偵測還是人臉識別?從技術角度上,NexVDO SDK 的人臉偵測 1:N 辨識率達到 99.8 的辨識率,就算是轉頭範圍近乎 90 度都能精準辨認。

NexVDO SDK 底層也涵蓋臉部 68 個 3D 特徵點識別,輔助想要實現人臉辨識的開發者不僅僅只能識別還可進一步的做表情辨識,我們提供平靜、驚訝、愉快、憤怒、厭惡與驚恐等 6 種表情分析。
延伸閱讀:特徵點越多,為什麼反而辨識率下降
智慧零售產業,常需要針對潛在客戶進行喜好分析,可從智慧看板蒐集的影像分析顧客的年齡與性別,有助於精準廣告內容推播,達到更高的行銷轉化率 ; 而在設計線上教學課程或是遠距教學業者,整合表情分析能輔助老師透過學生上課的狀態做課情分析,量化學習效率。NexVDO SDK 在人臉的部分,提供簡單的 API 介面從通用的人臉偵測到精準的表情識別,無論任何產業想要進行何種軟體開發應用,都能夠輕鬆的對接。
第三類行為分析模組應用於在連續影像上,對於人體姿勢或行為有分解需求的情境。

NexVDO SDK 在人體從頭到腳挑出 17 個關鍵偵測點,進而就能辨別當前的行為,例如:叉手、站立、坐著、躺下、舉手、跨越...等等。當行為結合連續性影像的立體空間定位,就會延伸更多實際的行為辨識,例如:轉身、跌倒、徘徊、丟東西...等等不同種的行為分析,從人體姿勢與空間定位,就能開展非常多應用。
延伸閱讀:何謂骨架關鍵點例如:棒球投手的訓練,透過 1080p240 的高速影像採集卡,分析投球的每一張畫面,經由 NexVDO SDK 提供的骨架關鍵點做姿勢分析,基於量化後的數據可引領他們有更卓越的表現!而在智慧長照中心,老年人的行為是最需要被注意的,一旦發生跌倒狀況要立刻協助否則後果不堪設想。以往需要長輩手上配戴智慧手環,但這讓部分長輩感到不自在,如果是能透過影像做零接觸的識別分析,不但使用廣泛且能在發生狀況時將影像留下紀錄。此外,聰泰也與教育業者逐步打造所謂的智慧課堂應用,課堂上的教材會結合攝影機的畫面,同步採集師生課堂互動的影像,並透過姿勢分析學生在課堂上的各種行為,老師若走動攝影機也能實時追蹤。
延伸閱讀:聰泰與IBase攜手用AI打造智慧教室透過 NexVDO SDK 的分析模組介紹可以看到, AI 影像分析已經在不同產帶來的巨大的轉變,聰泰一直以來的優勢就是已經與 nVIDIA TensoRT 及 Intel OpenVino 完整的整合,透過這些套件可以更有效地加速深度學習的推理及佈署,協助開發者縮短開發時程,從影像擷取到智能分析有光速的感受,讓你看到影像的同時也看到辨識結果!